For a change of pace today, I’ll present an incorrect proof of a simple proposition. The diligent reader can work out the location of the mistake before reading on, where I will present a modified proposition, and correct proof, before discussing the mistake in detail.
Proposition: If  is a field and
is a field and  is a cardinal less than
is a cardinal less than  , then a vector space over cannot be written as a union of of its proper subspaces.
, then a vector space over cannot be written as a union of of its proper subspaces.
Questionable Proof: Suppose that  is a collection of proper subspaces of
is a collection of proper subspaces of  , which cover . We can assume that no proper subcollection covers . (we can remove the superfluous elements from our collection if this is not the case) This implies that for each
, which cover . We can assume that no proper subcollection covers . (we can remove the superfluous elements from our collection if this is not the case) This implies that for each  , there exists some
, there exists some  such that
such that  for
for  .
.
Take any 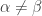 , and consider the set
, and consider the set  . This set has cardinality , and each element lies in some
. This set has cardinality , and each element lies in some  , so by the pigeonhole principle, two of these elements must lie in the same , say
, so by the pigeonhole principle, two of these elements must lie in the same , say 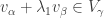 and
and 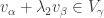 .
.
Subtracting, we see that 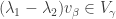 , so
, so 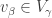 . Therefore
. Therefore 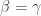 . Similarly, we see that
. Similarly, we see that 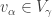 , so
, so 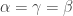 , contradiction.
, contradiction.
The above proposition is, unfortunately, false. To see this, take to be a real vector space with countably infinite basis  , and for each
, and for each  , let
, let  be the vector space generated by
be the vector space generated by 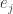 ,
,  . Then
. Then 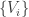 covers , even though it is a set of cardinality
covers , even though it is a set of cardinality  .
.
We need to add a condition to the proposition, but this time the proof is correct.
Modified Proposition: If is a field and is a cardinal less than , then a finite dimensional vector space over cannot be written as a union of of its proper subspaces.
Proof: We proceed by induction on the dimension. If has dimension  , then any union of proper subspaces must be the zero space, so the statement is trivial. Now assume that has dimension
, then any union of proper subspaces must be the zero space, so the statement is trivial. Now assume that has dimension  and the proposition has been proved for all vector spaces of dimension
and the proposition has been proved for all vector spaces of dimension  .
.
First, observe that there are at least subspaces of of dimension . For if  are a basis for , then we can take the subspaces generated by
are a basis for , then we can take the subspaces generated by 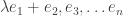 for
for  .
.
Suppose that we are given a collection of proper subspaces of of cardinality that covers . Since there are at least 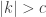 spaces of dimension , there must be such a space
spaces of dimension , there must be such a space  that is not equal to any
that is not equal to any 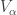 . Hence
. Hence 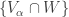 is a collection of proper subspaces of of cardinality that covers , contradiction.
is a collection of proper subspaces of of cardinality that covers , contradiction.
So what was the mistake in the original proof? You might question my use of the pigeonhole principle on infinite sets, but that can actually be made quite rigorous. No, the problem is the statement “We can assume that no proper subcollection covers “. Though an attractive idea, it is not true that we can reduce our collection to no longer be redundant.
Consider our earlier counterexample, a real vector space with a countably infinite basis. The given collection covers , but there is no non-redundant subcollection that does so. A slightly painful reminder that we must always modify our intuition when dealing with infinite sets.
We can salvage the original proof, however, when the collection is finite. Then, in fact, we can throw out elements of our collection, one at a time, until we have eliminated any redundancy. That gives us the following: (note that this is not strictly weaker than our modified proposition, since it applies to infinite-dimensional spaces as well)
Salvaged Proposition: If is an infinite field, a vector space over cannot be written as a union of finitely many proper subspaces.
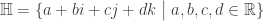
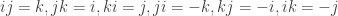





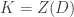

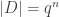

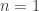



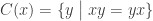

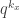

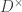





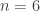




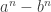
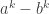

,
, and
is a power of
,

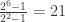
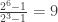
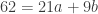






 Posted by lydianrain
Posted by lydianrain 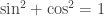 using power series wouldn’t be that big of a deal, he said that this was “a rash thing to do” and that I would “end up summoning Cthulhu doing weird shit like that.”
using power series wouldn’t be that big of a deal, he said that this was “a rash thing to do” and that I would “end up summoning Cthulhu doing weird shit like that.”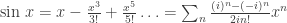

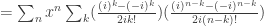
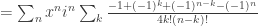
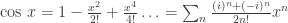
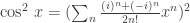
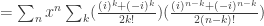
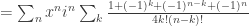
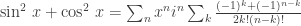
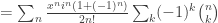
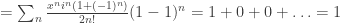
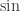 and
and 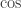 is the periodic sequence
is the periodic sequence 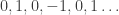 . And surely the mathematical techniques for manipulating this series can be no simpler than the series itself! In other words, I feel that my observation that we can write this sequence as
. And surely the mathematical techniques for manipulating this series can be no simpler than the series itself! In other words, I feel that my observation that we can write this sequence as 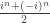 was just notational convenience and nothing more. My own style is to prefer algebra to case analysis because I tend to make more mistakes in the latter.
was just notational convenience and nothing more. My own style is to prefer algebra to case analysis because I tend to make more mistakes in the latter.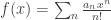 and
and 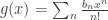 , then
, then 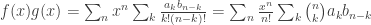 . Nothing special here; just the distributive law. (if you are interested in going deeper into these kinds of manipulations of sequences, I highly recommend Wilf’s
. Nothing special here; just the distributive law. (if you are interested in going deeper into these kinds of manipulations of sequences, I highly recommend Wilf’s 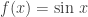 and
and 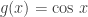 , then
, then  and
and  are the sequences
are the sequences 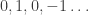 and
and 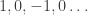 respectively.
respectively.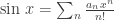
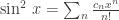
 , and
, and

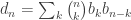
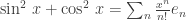
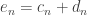 .
.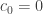 and
and 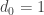 , so
, so 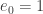 . All that remains to be shown is that
. All that remains to be shown is that 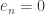 for all
for all 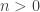 .
. for all
for all 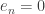 .
.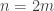 is even. Then
is even. Then 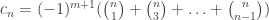 and
and 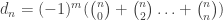 . Hence
. Hence 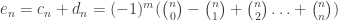
 .
. .
.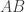 ,
, 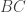 and to replace them with three segments
and to replace them with three segments  ,
, 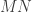 ,
, 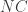 , where
, where  is the midpoint of
is the midpoint of  is the midpoint of
is the midpoint of 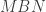 to obtain a convex
to obtain a convex 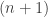 -gon. A regular hexagon
-gon. A regular hexagon  of area
of area  . Then
. Then  and so on. Prove that no matter how the clippings are done, the area of
and so on. Prove that no matter how the clippings are done, the area of  is greater than
is greater than 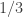 for all
for all  .
. be a convex polygon with
be a convex polygon with 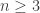 . Any set of
. Any set of 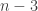 diagonals that do not intersect in the interior of a polygon determine a triangulation of
diagonals that do not intersect in the interior of a polygon determine a triangulation of 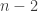 triangles. If
triangles. If 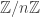 is more interesting than it is often given credit for. This post will tell you the isomorphism type of its group of units.
is more interesting than it is often given credit for. This post will tell you the isomorphism type of its group of units. is any ring with unity, there exists a unique
is any ring with unity, there exists a unique 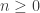 and injective homomorphism
and injective homomorphism  .
.  , and we factor out its kernel (which is of the form
, and we factor out its kernel (which is of the form  ,
,  being a
being a 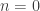 is disproportionately common).
is disproportionately common).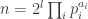 , where the product is over odd primes, the group of units
, where the product is over odd primes, the group of units 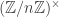 can be written as a product of cyclic groups
can be written as a product of cyclic groups  when
when 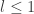 and
and  when
when 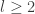 . In particular, the group of units is cyclic exactly when
. In particular, the group of units is cyclic exactly when 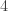 .
.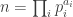 , then
, then  . So we only need to address the question when
. So we only need to address the question when  is a power of a prime.
is a power of a prime. ? If
? If 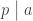 , then
, then 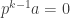 , so
, so  cannot be invertible. Those who are quick on the draw with the number theory will be able to quickly show that if
cannot be invertible. Those who are quick on the draw with the number theory will be able to quickly show that if 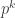 are relatively prime, so we can choose integers
are relatively prime, so we can choose integers  and
and  such that
such that  )
)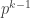 elements divisible by
elements divisible by 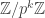 has
has 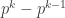 units. (notice that this, along with the
units. (notice that this, along with the 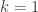 is actually the most difficult. It is a special case of a theorem which says that a finite subgroup of the multiplicative group of any field is cyclic. For a proof of this case, see e.g.
is actually the most difficult. It is a special case of a theorem which says that a finite subgroup of the multiplicative group of any field is cyclic. For a proof of this case, see e.g.  is a generator for the group of units of
is a generator for the group of units of  . Then the order of
. Then the order of  is divisible by
is divisible by 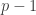 , so it is of the form
, so it is of the form 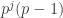 . Then
. Then  has order
has order 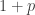 has order
has order  has order
has order  .
.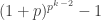 is divisible by
is divisible by  with
with 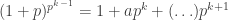 .
. , the group of units of
, the group of units of  is the product of two cyclic groups, one of order
is the product of two cyclic groups, one of order 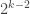 . If
. If  , the group of units of
, the group of units of 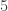 generates a cyclic group of order
generates a cyclic group of order  , an element of order
, an element of order  will work) We first show, by induction on
will work) We first show, by induction on 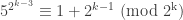 , the case
, the case 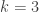 being clear.
being clear.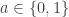 such that
such that 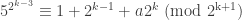 . Squaring, we get
. Squaring, we get 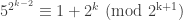 .
.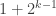 is an element of order
is an element of order 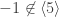 . But a cyclic group can contain at most one element of order
. But a cyclic group can contain at most one element of order 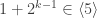 .
. , giving a homomorphism
, giving a homomorphism 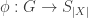 . A basic example would be the cyclic group
. A basic example would be the cyclic group 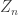 acting on an
acting on an  :
: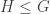 ,
,  by left multiplication.
by left multiplication. . For an example of this technique, let’s consider this classic problem:
. For an example of this technique, let’s consider this classic problem: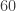 is isomorphic to
is isomorphic to 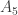 . (recall that a simple group is one with no nontrivial normal subgroups)
. (recall that a simple group is one with no nontrivial normal subgroups)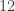 and is congruent to
and is congruent to 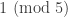 , so
, so 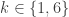 . If
. If 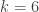 .
.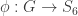 . Because none of these subgroups can be normal (or again appealing to Sylow theory) it is easy to see that
. Because none of these subgroups can be normal (or again appealing to Sylow theory) it is easy to see that 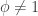 , so
, so  . But
. But 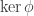 is a normal subgroup of
is a normal subgroup of  and
and  is injective.
is injective.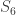 . In fact,
. In fact, 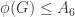 , as the following lemma will tell us:
, as the following lemma will tell us: is a simple group of order larger than
is a simple group of order larger than 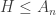 .
.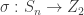 be the sign homomorphism, so
be the sign homomorphism, so 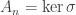 . Then
. Then 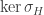 is a normal subgroup of
is a normal subgroup of  cannot be injective, as
cannot be injective, as  , so
, so  , in other words
, in other words  .
. . Counting orders, we see that
. Counting orders, we see that 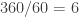 . Let
. Let 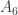 act on the set of left cosets of
act on the set of left cosets of 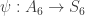 . Pausing for a moment to verify that
. Pausing for a moment to verify that  , the fact that
, the fact that  is injective, and applying the lemma tells us easily that
is injective, and applying the lemma tells us easily that 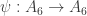 is an isomorphism.
is an isomorphism.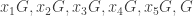 . Multiplication on the left by elements of
. Multiplication on the left by elements of  . So
. So 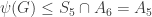 .
.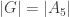 , it follows that
, it follows that  is a finite set and
is a finite set and  is a function, then
is a function, then 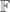 is a finite field and
is a finite field and  is a homomorphism of fields, then
is a homomorphism of fields, then  ) so
) so 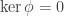 and
and 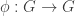 is a homomorphism, then
is a homomorphism, then 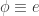 .
.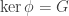 , in which case
, in which case  , in which case
, in which case 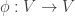 is a linear transformation, then
is a linear transformation, then  is an integral domain containing
is an integral domain containing  , and consider the map
, and consider the map 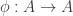 defined by
defined by 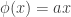 . Then
. Then  with
with  , so
, so 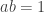 .
. is injective, and if
is injective, and if 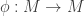 is surjective. (hint: in fact, for any
is surjective. (hint: in fact, for any  . If
. If  .)
.) possess geometric properties that intertwine with their analytic properties in surprising and beautiful ways. This is hardly a place to discuss the subject in detail, so I will focus on Rouché’s Theorem, with an entertaining application.
possess geometric properties that intertwine with their analytic properties in surprising and beautiful ways. This is hardly a place to discuss the subject in detail, so I will focus on Rouché’s Theorem, with an entertaining application. is an open disc in
is an open disc in  and
and  are complex-valued differentiable functions defined in some neighborhood of
are complex-valued differentiable functions defined in some neighborhood of 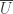 , and if
, and if  on the boundary of
on the boundary of  if
if  but
but  , and a zero of multiplicity two if
, and a zero of multiplicity two if 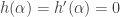 but
but  , etc.
, etc. , the polynomial
, the polynomial  is irreducible.
is irreducible. , and let
, and let 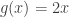 . Choose
. Choose 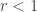 to be sufficiently close to
to be sufficiently close to  .
. , we have
, we have 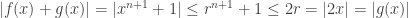 , so
, so  . Letting
. Letting 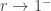 , we find that
, we find that 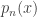 must have exactly one root
must have exactly one root 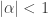 .
. were a root of
were a root of  with
with  . Then
. Then 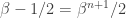 , so
, so 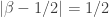 . So
. So  of radius
of radius 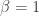 . Since
. Since 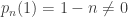 ,
,  over the integers, then the constant terms of
over the integers, then the constant terms of  must be
must be  . But these constant terms are the product of some subset of the roots of
. But these constant terms are the product of some subset of the roots of 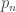 . If
. If 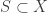 is dense, then any continuous map
is dense, then any continuous map 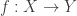 is determined by its values on
is determined by its values on 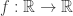 , for example.
, for example.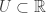 , we can construct a
, we can construct a 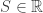 is not dense, then continuous functions
is not dense, then continuous functions 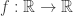 are not determined by their values on
are not determined by their values on  and two distinct continuous functions
and two distinct continuous functions 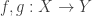 that agree on
that agree on 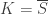 , and let
, and let 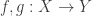 are distinct, but agree on
are distinct, but agree on  space
space 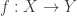 , where
, where 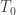 if for any two distinct points
if for any two distinct points  , or Hausdorff, if for any two distinct points
, or Hausdorff, if for any two distinct points  is an open set if
is an open set if 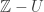 is finite.
is finite.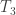 ,
, 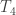 ,
,  , and
, and 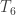 . So why is the Hausdorff axiom so important?
. So why is the Hausdorff axiom so important? is called dense if every nonempty open set
is called dense if every nonempty open set  contains a point from
contains a point from  is dense. Notice that any continuous function
is dense. Notice that any continuous function 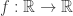 is determined entirely by its values on
is determined entirely by its values on  . This can be generalized:
. This can be generalized: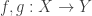 are continuous and not equal. Then
are continuous and not equal. Then 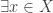 such that
such that 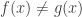 .
.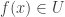 and
and  . Then
. Then  is a nonempty open set in
is a nonempty open set in 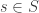 . Hence
. Hence 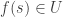 and
and  , so
, so  , and
, and 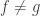 on
on 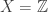 with the cofinite topology.
with the cofinite topology.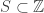 is infinite, then
is infinite, then 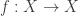 is continuous. But a bijection cannot be determined by its value on all but two points, so if we choose
is continuous. But a bijection cannot be determined by its value on all but two points, so if we choose  contains at least two points, then continuous functions
contains at least two points, then continuous functions 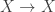 are not determined by their value on
are not determined by their value on 